[DB] Single Block I/O vs Multi Block I/O
SQL 서적을 읽던 중 Single Bolck I/O와 Multi Block I/O에 관한 설명을 접하게 되었고 지금까지 개발을 하면서 지금까지 생각해 왔던 것과는 다른 새로운 개념을 알게 되어 글로 작성하였다.
DB에서 I/O란?
- SQL이 느려지는 이유는 보통 디스크 I/O 때문이라고 보면 된다.
- 책에서는 I/O = 잠(Sleep)이라고 표현했다.
- OS 또는 I/O 서브시스템이 I/O를 처리하는 동안 프로세스는 잠을 자기 때문이다. 즉, I/O를 처리하는 동안 다음 동작을 행할 수 없으니 텀이 발생하게 되고 이것을 "잠"이라고 표현한 것 같다.
Single Block I/O?
- 한 번에 한 블록씩 요청해서 메모리에 적재하는 방식
- 인덱스가 보통 Single Block I/O 방식으로 디스크에 접근하여 데이터를 가져온다.
Multi Block I/O?
- 한 번에 여러 블록씩 요청해서 메모리에 적재하는 방식
- 인덱스를 이용하지 않고 테이블 전체를 스캔할 때 보통 Single Block I/O 방식으로 디스크에 접근하여 데이터를 가져온다.
- 캐시에서 찾지 못한 특정 블록을 읽으려고 I/O Call 할 때, 디스크 상에 그 블록과 '인접한' 블록들을 한꺼번에 읽어 캐시에 미리 적재하는 기능
Block 이란?
- 블록의 개념을 알기 위해선 우선 데이터 베이스의 저장 구조를 알아야 한다.
- 테이블 스페이스는 세그먼트를 담는 컨테이너로서, 여러 개의 데이터파일로 구성된다.
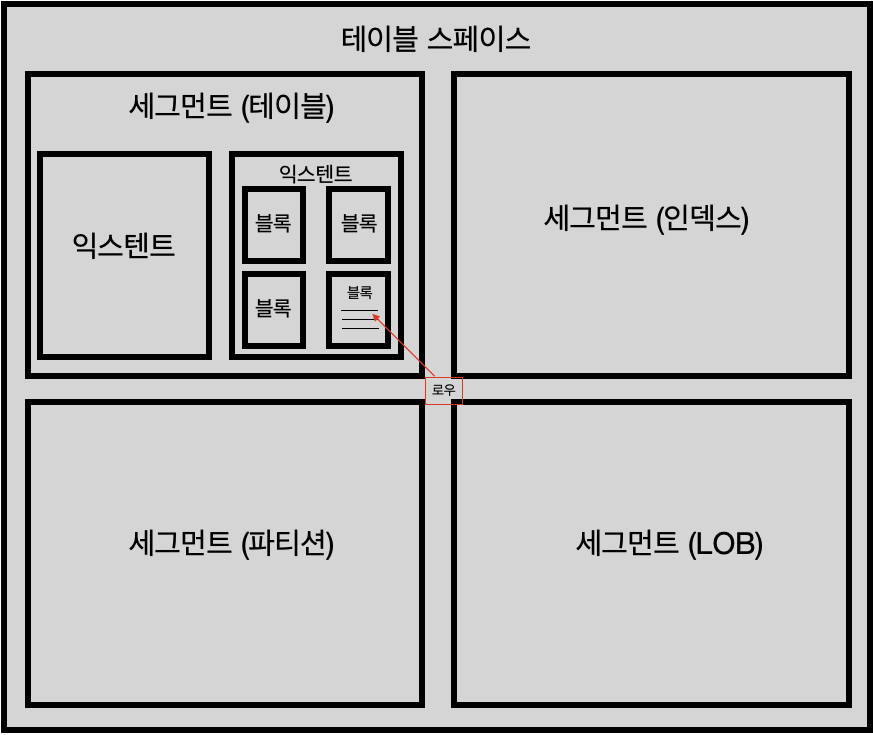
| - 블록: 데이터를 읽고 쓰는 단위 - 익스텐트: 공간을 확장하는 단위 - 세그먼트: 데이터 저장공간이 필요한 오브젝트(테이블, 인덱스, 파티션, LOB 등) - 테이블 스페이스: 세그먼트를 담는 콘테이너 - 데이터 파일: 디스크 상의 물리적인 OS파일 |
메모리에 적재하는 이유는?
- DB에서 데이터는 메모리 캐시에 데이터가 존재할 경우 메모리캐시에서 데이터를 갖고 오며 DB 버퍼캐시에서 원하는 데이터를 찾지 못한다면 디스크에서 읽기 위해 I/O Call을 진행한다.
- 튜닝의 기초를 말할 때 보통 디스크 I/O를 줄이는 것을 우선으로 말한다. 이 디스크 I/O를 가장 확실하게 줄일 수 있는 방법이 메모리 캐시를 이해하고 I/O를 적절히 사용하는 것이다.
그래서 뭐가 더 좋은데?
- 정답은 없다. 각 상황에 맞춰 적절한 방식으로 디스크 I/O를 해야지만 비용을 줄일 수 있는 것이다.
- 이 책을 읽기 전까지 어떤 데이터든 당연히 인덱스를 걸면 비용이 줄어들고 효율이 높아지는 것이라 생각했다. 하지만, 이 책에서 나온 내용은 때로는 Multi Bolck I/O 즉, Table Full Scan을 하는 것이 어쩌면 가장 쉬운 튜닝 방법일 것이라고 말하고 있다.
참조: 친절한 SQL 튜닝